Jupyter NotebookをGoogle Cloudのサーバーレス上で実行する
2022-08-13

#はじめに
Jupyter Notebookは、データ分析をするのに便利なツールです。昨今の機械学習などで機械学習エンジニアが好んで使っています。
ただ、せっかく作ったNotebookをわざわざ本番実行する際には、Pythonコードに直したりしている場面を見たことがあります。
これは本末転倒だなあと思ったことがあります。
そこで、Jupyter NotebookをGoogle Cloudのサーバーレス上で直接実行できるようにしたいと思います。
この記事の全コードは
GitHub
を参照ください。
下記のボタンを押すとCloud Shellを起動して、Cloud Run上で実行することを試すことができます。

#Jupyter Notebookの実行方法
papermillというソフトウェアを使うと、簡単にJupyter Notebookを実行できます。
papermillの実行は、いくつか方法があります。
- Python APIから実行する
import papermill as pm
pm.execute_notebook(
'path/to/input.ipynb',
'path/to/output.ipynb',
parameters = dict(alpha=0.6, ratio=0.1)
)- CLIから実行する
papermill local/input.ipynb s3://bkt/output.ipynb -p alpha 0.6 -p l1_ratio 0.1今回は別のマイクロサービスからAPI経由で呼び出したいのでPython APIから実行する方式を採用して、FlaskでWebAPIを提供する形にしようと思います。
#サーバーレス環境
papermillは並行で動かすことは向いていないようなので、1リクエストに対して1インスタンスの並行処理を制御できるサービスを使います。
-
選択肢
-
Cloud Functions
第1世代は、ひとつのインスタンスに対してひとつのHTTP Requestが実行されます。
また、第2世代では、自動スケールできますが、この場合でも
インスタンスの最大数を1に設定しておけばよいでしょう。 -
Cloud Run
CloudRunでは、
コンテナあたりの最大リクエスト数を設定できます。この値を1に設定しておくとよいでしょう。
-
#Flask Web App
デモなので最低限のことしかしていません。
- Papermillを実行するときにリクエストに応じてNotebook名とParametersを渡す。
- Papermillの実行結果をスクラップブック経由で取得して、JSONで返す。
# -*- coding: utf-8 -*-
from flask import Flask, request
import papermill as pm
import scrapbook as sb
import os
app = Flask(__name__, static_url_path="")
@app.route("/papermill/<notebook_name>", methods=["POST"])
def papermill_execute(notebook_name):
output = os.path.join('/tmp',
f'{notebook_name}.out.ipynb')
# papermillを実行する
pm.execute_notebook(
f'notebooks/{notebook_name}.ipynb',
output,
parameters=request.json
)
# 結果をスクラップブックで取得する
res = sb.read_notebook(output).scraps['result']
return res.data
if __name__ == "__main__":
app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))#Notebook
こちらもデモなので最低限のことしかしていません。Hello Worldを実行しています。
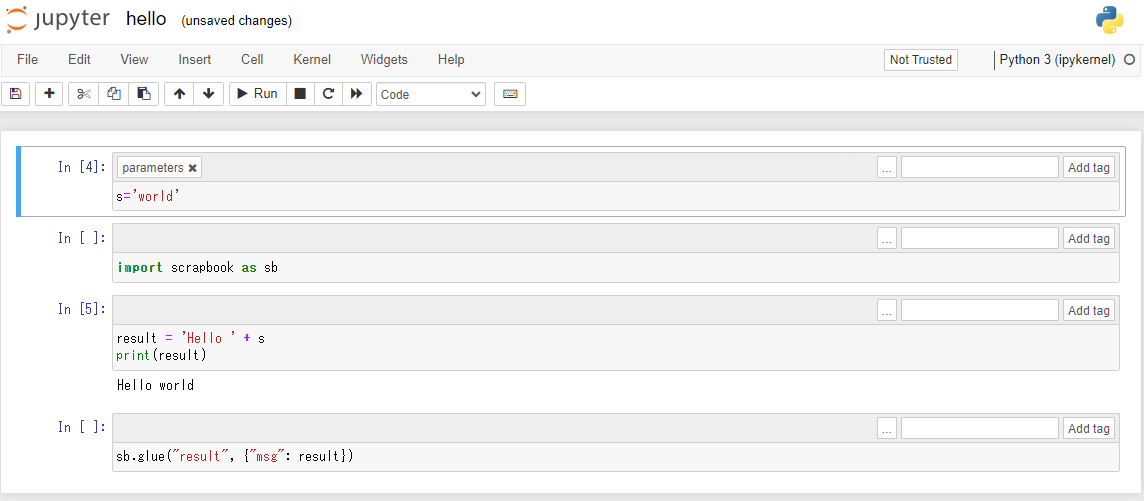
#実行
Cloud RunにデプロイするとURLが発行されますますので、curlをつかって呼び出してみます。
curl https://article-20220813-3jvhktedhq-uc.a.run.app/papermill/hello \
-H "Content-Type: application/json" \
-d '{"s":"papermill"}'
{"msg":"Hello papermill"}
実行結果のログを見るとおよそ5秒程度の実行時間がかかっています。バッチ処理などバックグラウンド処理から呼び出すようなケースでは使えそうです。
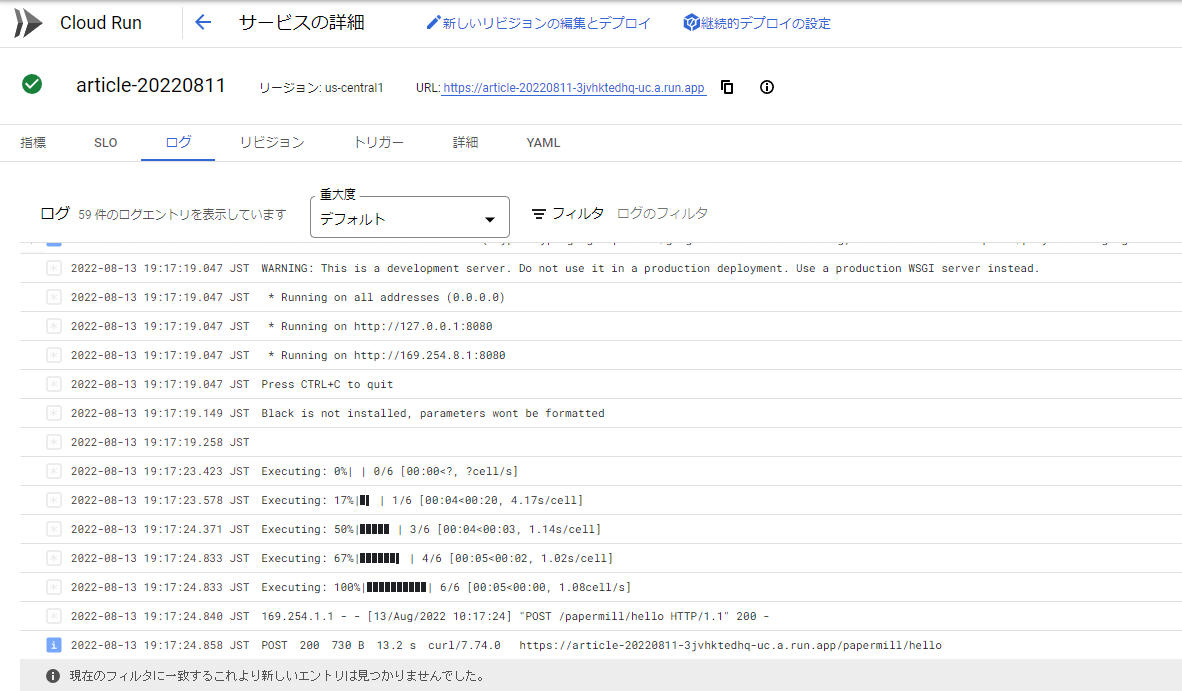
第1世代のCloud Runでは下記のようなSystemCallに関するログが出たので、第2世代を使うほうが無難そうです。第1世代でも一応動きましたが。
Container Sandbox: Unsupported syscall UNKNOWN[435/0x1b3](0x3e48c02cedc0,0x58,0x3e4ae3e94850,0x8,0x3e4ac5200640,0x3e48c02ceedf). It is very likely that you can safely ignore this message and that this is not the cause of any error you might be troubleshooting. Please, refer to https://gvisor.dev/docs/user_guide/compatibility/linux/amd64/#UNKNOWN[435/0x1b3] for more information.
#その他
本番環境で利用するには認証に関することや、Google CloudのAPIを使う場合はサービスアカウントの設定など考える必要があります。今回のデモはHelloWorldなので、文字列を渡すだけでしたが、分析ユースケースでは、DBにアクセスしたり、ファイルにアクセスしたりすることがあるので、具体的にはCloudStorageにアクセスできるようにしたり、BigQueryやCloudSQLにアクセスできるようにするなどは、考えられます。
また、Papermillでは、Input/OutputのNotebookをGCSやS3などクラウドのストレージに直接アクセスできる機能があるので、結果を残しておいて後から確認できるようにするのは、便利だと思います。
#まとめ
今回は、Jupyter NotebookをGoogle Cloudのサーバーレス上で実行しました。
NotebookをWebAPIとして、そのまま実行できるのは、とても便利だと思いました。当然、実行時間はかかるので、用途は限られると思いますが、少なくともNotebookで作ったロジックを、Pythonのソースコードに書き換えるような手間はなくなると思います。
