Datastreamを使って、CloudSQLからBigQueryへストリーミングレプリケートする
2023-05-03

#はじめに
今回は、Google CloudのDatastream for BigQueryというサービスを紹介したいと思います。
データ基盤を構築する際に、マスタデータをBigQuery上にコピーして分析を行うというケースは多いと思います。
#Datastreamとは
Datastream は、サーバーレスで使いやすい変更データ キャプチャ(CDC)とレプリケーション サービスです。Datastream を使用すると異種のデータベースやアプリケーションの間でデータを確実に、かつ最小限のレイテンシとダウンタイムで同期できます。
引用元:Datastream の概要 | Google Cloud
これに加えて今回紹介するDatastream for BigQueryはリレーショナル データベースから BigQuery へのシームレスなレプリケーションを実現するサーバーレスのマネージドサービスです。
Datastreamの変更データ キャプチャ (CDC) と BigQueryのStorage Write API の UPSERT 機能を組み合わせて、リレーショナル データベースから BigQuery へのストリーミング レプリケーションを実現されているようです。
#試してみる
前提として、既存のプロジェクトでCloudSQLのPostgreSQLがあるのでこれを使います。
- 構成図
検証目的なのでPublicIPによるアクセスを許可しています。商用環境では、要件によってはVPCからしかアクセスできないこともあると思います。そのような場合、CloudSQLであれば、プライベート接続を検討すると良いと思います。

- 始める
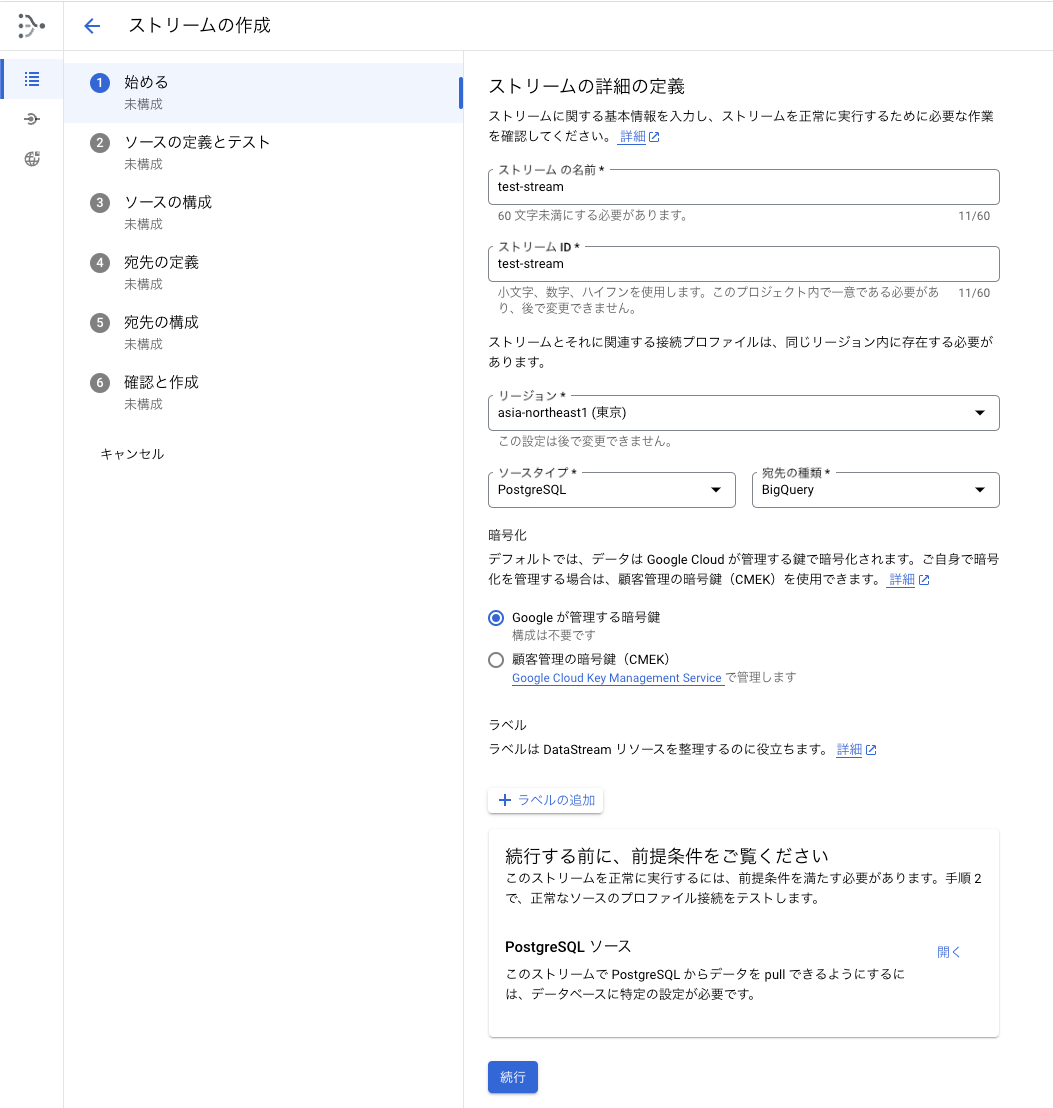
コンソールからデータストリームを選択して、ストリームの作成を選択すると、以下のようなウィザード画面が表示されます。
- ソースの定義とテスト
CloudSQLの接続情報を入力します。
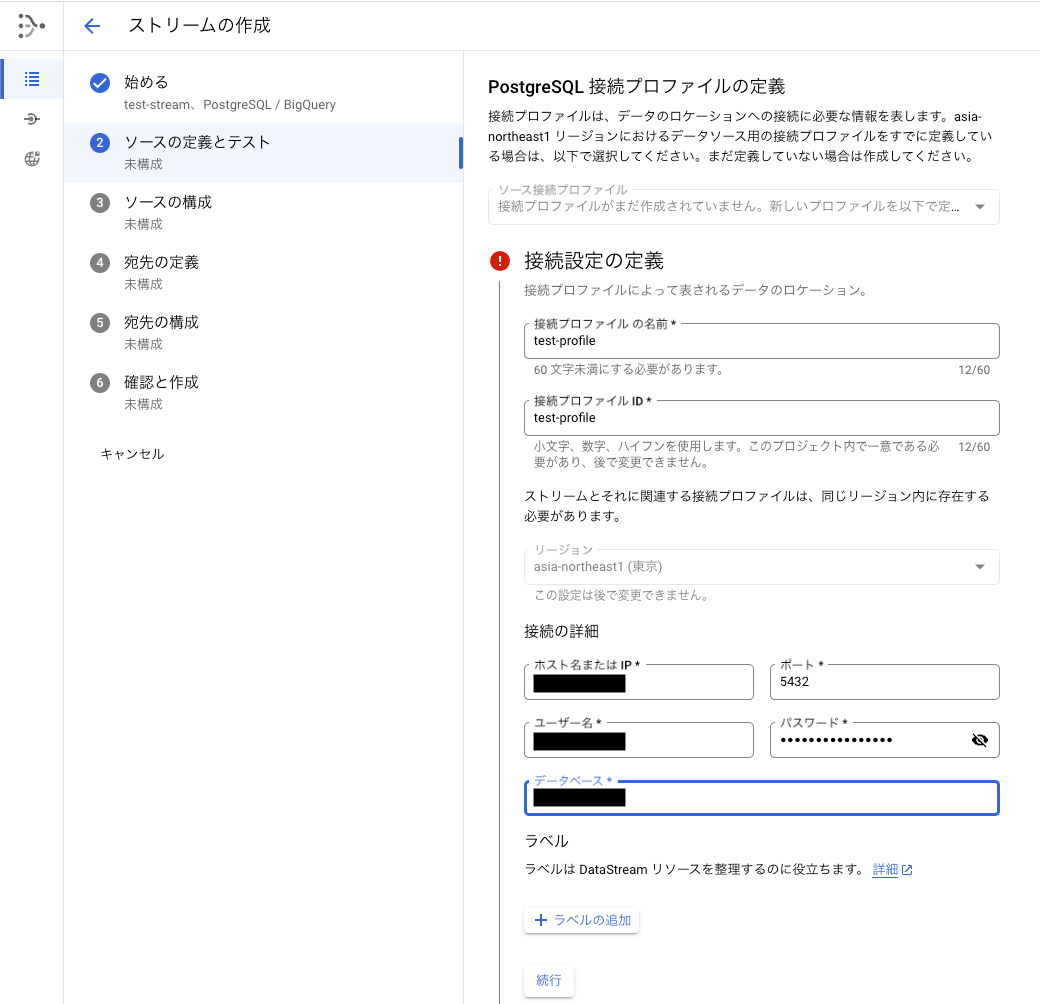
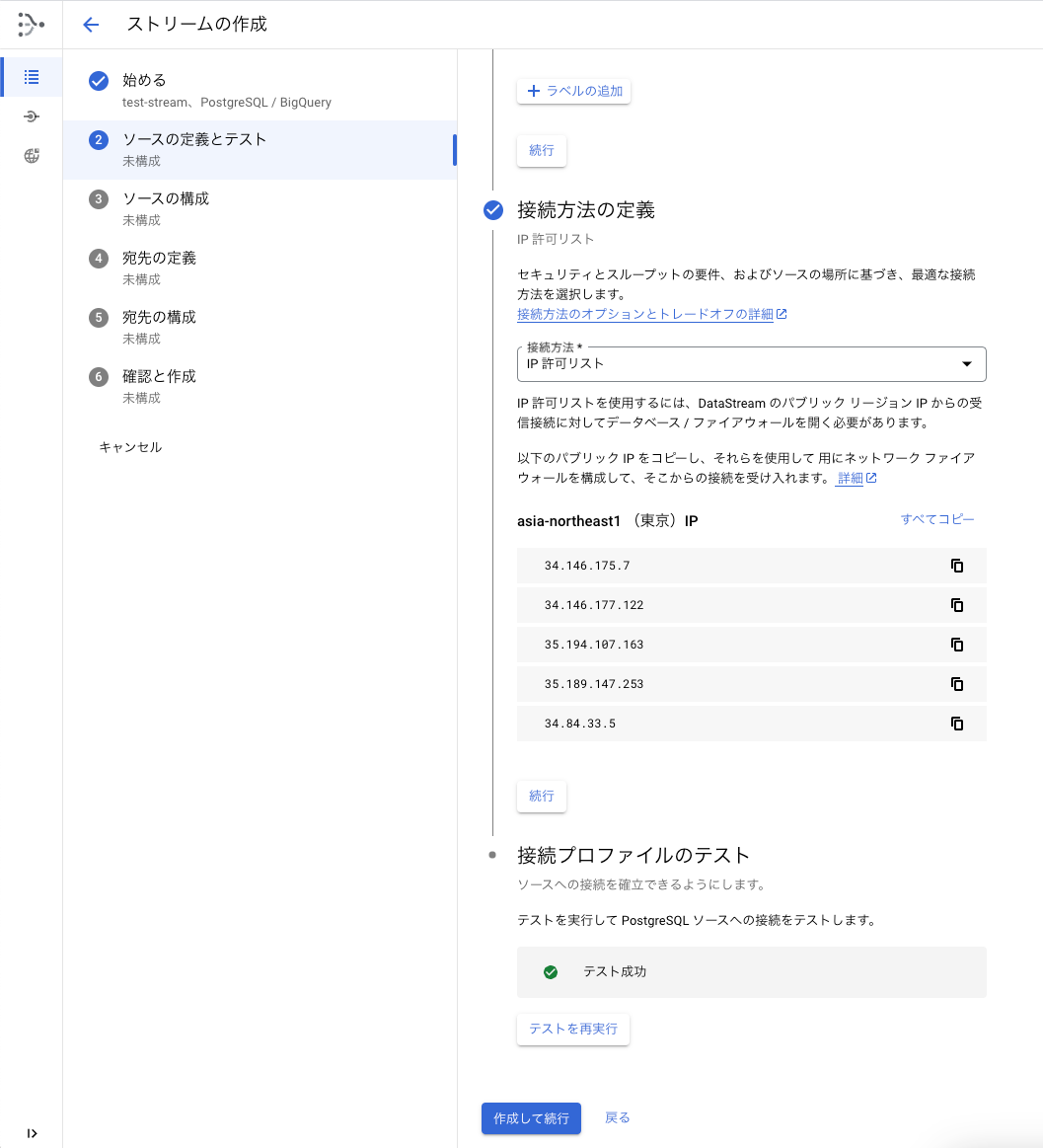
接続方法は、IP許可リストを選択します。接続プロファイルのテストを行って成功すればOKです。
CloudSQL側で、表示されているIPアドレスを許可しておく必要があります。
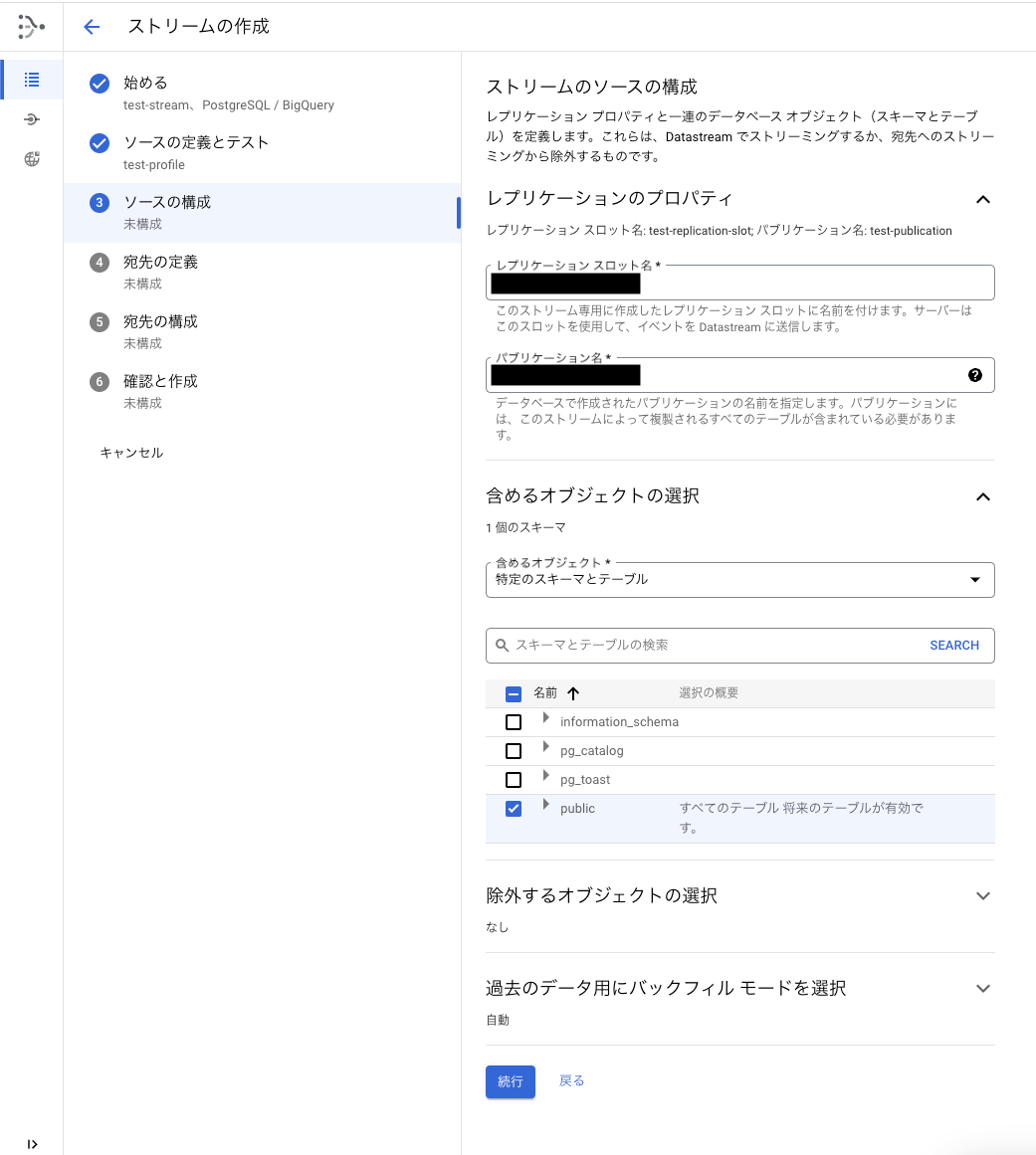
 3. ソースの構成
3. ソースの構成
変更データキャプチャの設定とレプリケートする対象テーブルの設定などを行います。
変更データキャプチャの設定は、ドキュメントがあるのでこちらを参考にするとよいでしょう。
REPLICATION_SLOT_NAMEとPUBLICATION_NAMEを入力します。
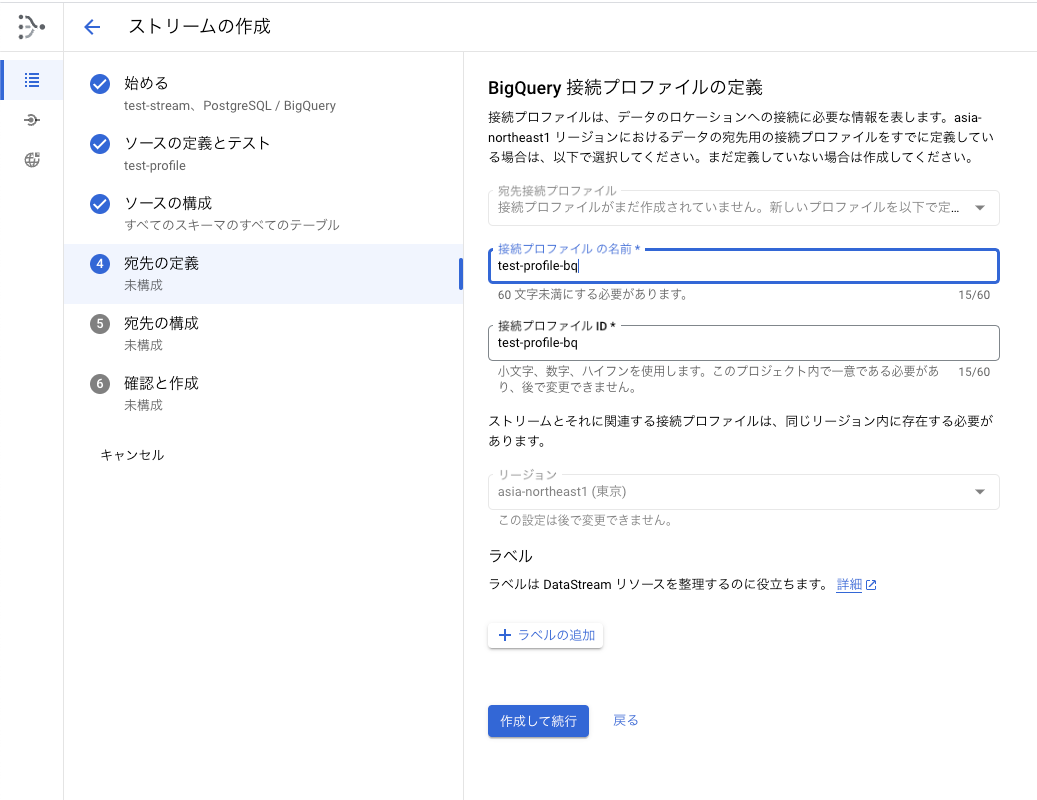
 4. 宛先の定義
4. 宛先の定義
宛先の設定を行います。
 5. 宛先の構成
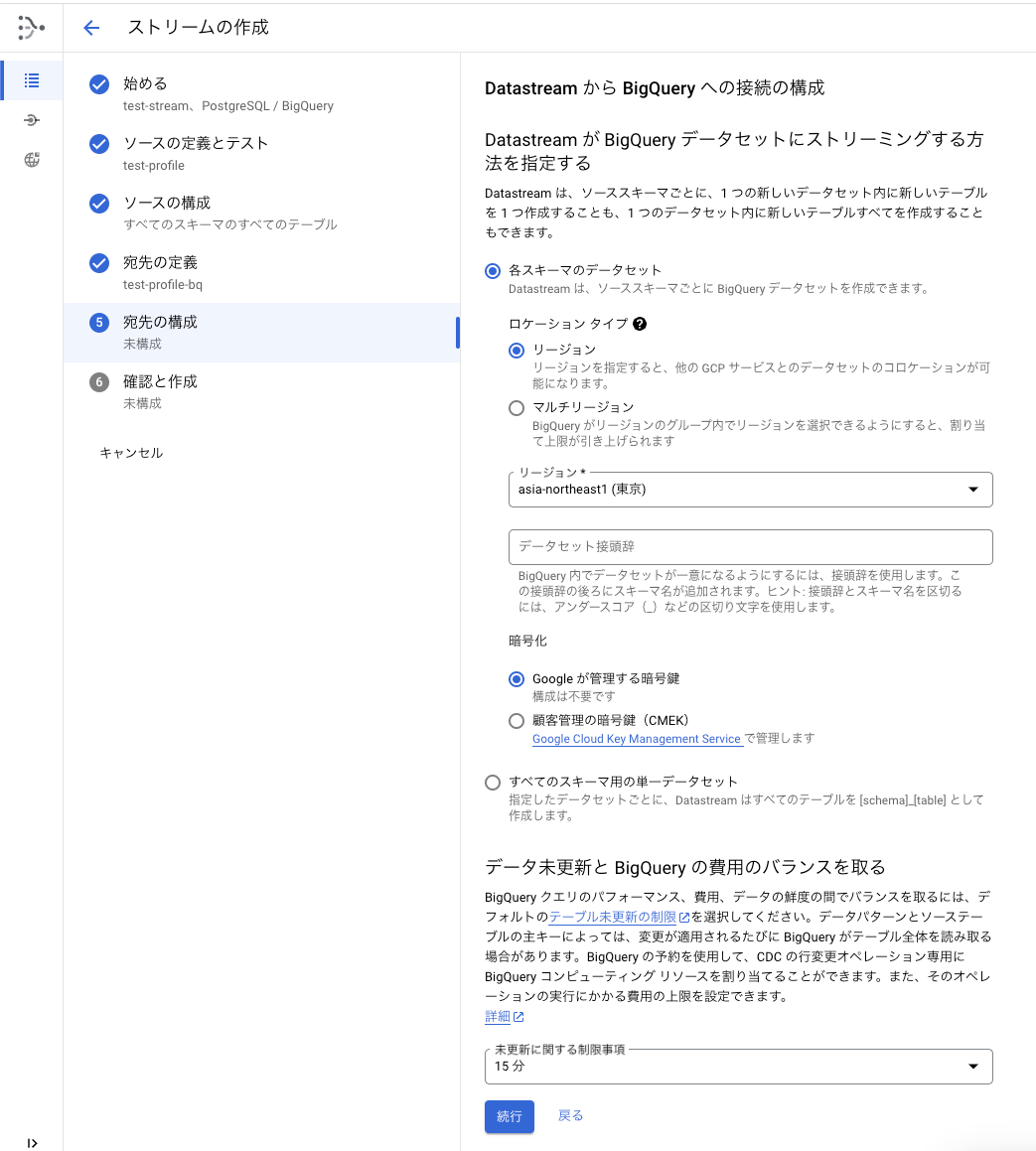
5. 宛先の構成
宛先のデータセットをどのように構成するかを設定します。
 6. 確認と作成
6. 確認と作成
最後にエンドツーエンドのテストができるので、テストを行なって問題なければ、ストリームを作成・開始します。
#動作確認
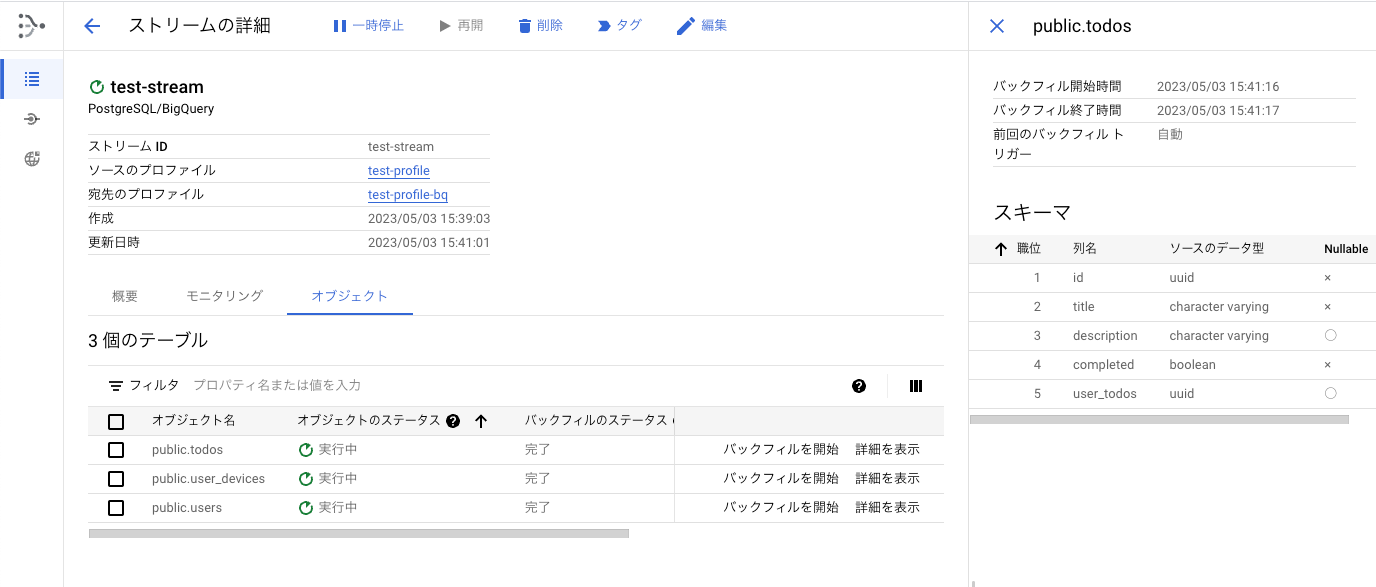
ストリームを作成して開始すると、以下のような画面が表示されます。実際にCloudSQLにあるテーブルの一覧が表示され、ストリームが動作していることが確認できます。
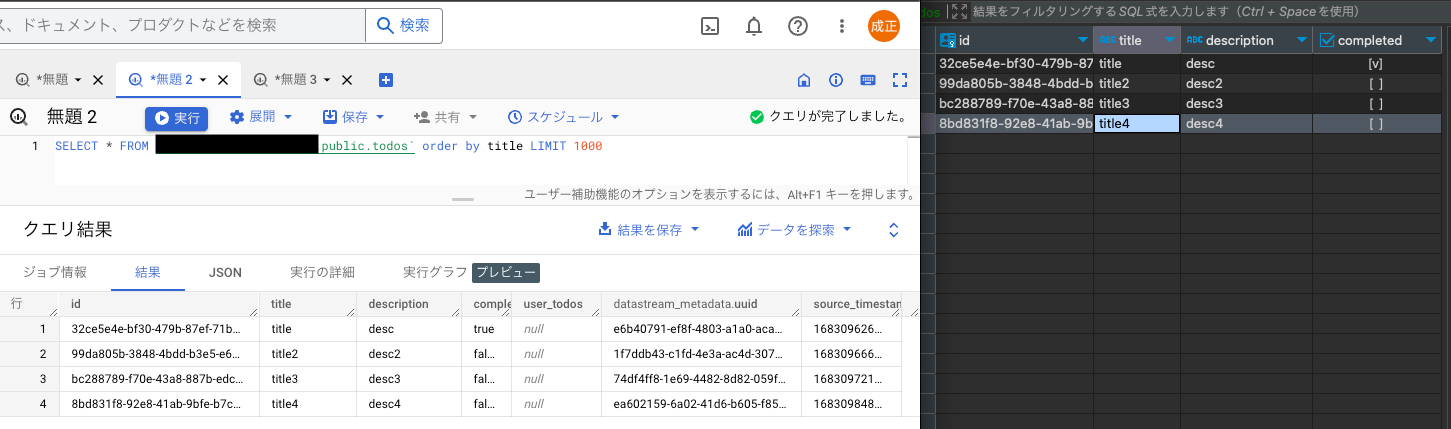
BigQueryから同期できているかを確認します。BigQueryのコンソール画面と、右側はローカルからCloudSQLに繋いで同じテーブルをデータの比較してみます。設定によるのですが10分程度、同期されるのに時間がかかりました。後述しますが、この辺りの挙動はドキュメントを参照して理解を深めておきたいです。もちろん、数秒から数十秒で同期できることも確認できましたので、ニアリアルタイムでレプリケーションできるというのは事実です。
#感想・考察
手動で設定してみて、PostgreSQLのレプリケーションスロットとパブリケーションの設定に慣れておらず、少し躓きましたが、30分程度でレプリケーションできたので、かなりタイムパフォーマンス高いなと思いました。
CloudSQLのテーブルがニアリアルタイムで同期できるのは、結構感動しました。少し同期周りの挙動を理解するの時間がかかりました。
- IaC
手動設定でも作れますが、Terraformなどを利用して各種環境で再利用するのが良いでしょう。
幸いすでにTerraformのリソースがあるので、こちらを参考にすると良いでしょう。
- リアルタイム性とコストのトレードオフ
詳しくは、こちらのドキュメントを参照ください。
きちんと理解できているか怪しいですが、ドキュメントを読むと、同期される(UPSERT)されるタイミングは、upsert_stream_apply_watermark(UPSERTが最後に実行されたタイムスタンプ)からテーブルに設定されているmax_stalenessの時間が経過している、かつ、クエリが呼び出されたタイミングと読み取れました。
max_stalenssは下記のようなSQLで確認・変更できます。
-- 変更
ALTER TABLE employees
SET OPTIONS (
max_staleness = INTERVAL 15 MINUTE);
-- 確認
SELECT
option_name,
option_value
FROM
mydataset.INFORMATION_SCHEMA.TABLE_OPTIONS
WHERE
option_name = 'max_staleness'
AND table_name = 'mytable';実際にこれらの値を変更してみて、同期されるタイミングを確認してみました。max_stalenessとクエリを呼び出すというのが関係していそうです。
max_stalenessをゼロに設定した場合は、数秒から数十秒でBigQueryのクエリを叩くと同期されていました。
ちなみに、Google Cloudのコンソールの画面上からクエリを叩いても、クエリによってはキャッシュが効いてしまっているのか、同期されないことがありました。動作確認するときは、キャッシュをオフにすることを意識しておくと良いでしょう。
max_stalenessの設定とクエリの呼び出しによりリアルタイム性とコストのトレードオフを調整できるので、適切に設定することが重要です。
この辺は実際に計測しないとわからないので、実際にストリームを作成して、適切な設定を行うことをおすすめします。
- セキュリティ
CloudSQLへの接続は、前述しましたが、商用環境などでは、IP許可リストではなく、プライベート接続すると良いでしょう。
- 運用
いくつか制約があることを導入する前に確認しておくと良いでしょう。
データスキーマの変更は後方互換を意識して戦略的に破壊が起こらないよう実施するのがおすすめです。
列のドロップなどいくつかの変更では、データの破壊や失敗することが言及されています。
バックフィルを実施することで過去に遡ってデータを同期することができます。障害などによってデータが欠落した場合などに利用できるので、運用時には覚えておくと良いでしょう。
- 料金
Datastream自体のコストは主にCDCのデータ転送量によって決まるようです。従量課金なので小さく始める場合でも選択しやすいと思います。
#まとめ
今回は、Google CloudのDatastream for BigQueryを紹介しました。
リレーショナルデータベースをBigQueryに同期することで、他のデータとクロス分析するなどもコンピューティング能力を気にせず可能になるので、データ分析基盤を構築する際には、検討してみると良いでしょう。
また、リアルタイム性も高くできるので、これまでバッチ処理していた部分を置き換えると用途が広がりそうです。
